闲得无聊,我只能继续重复造轮子度日了。
参数说明:
python cnvd.py -n 编号1,编号2
运行截图
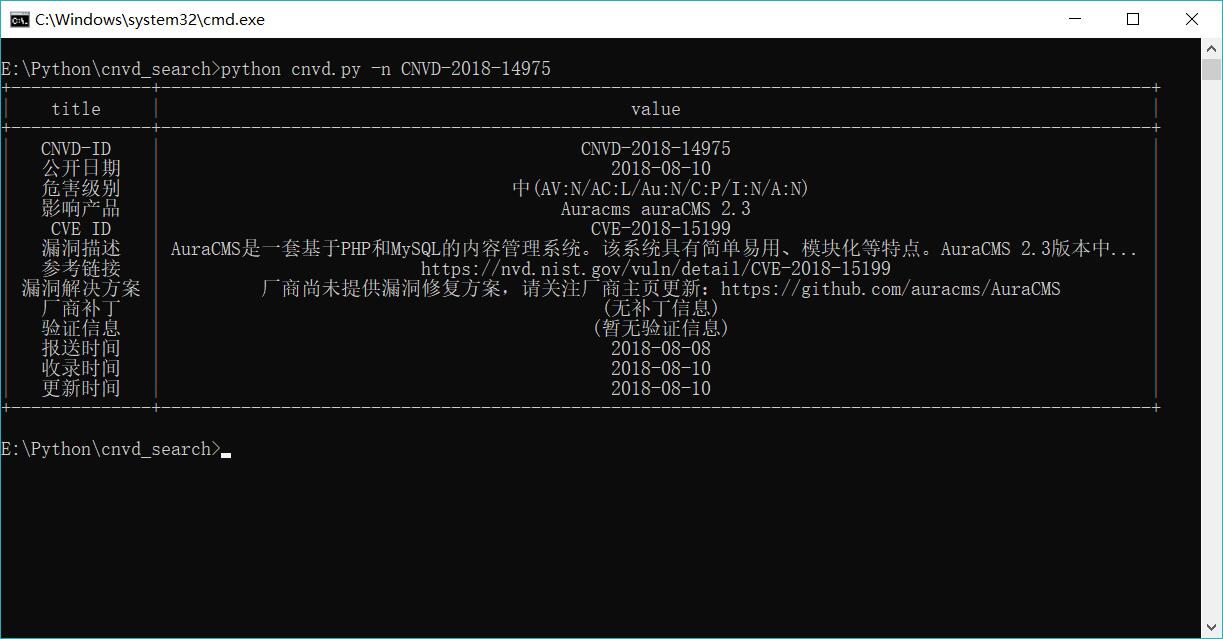
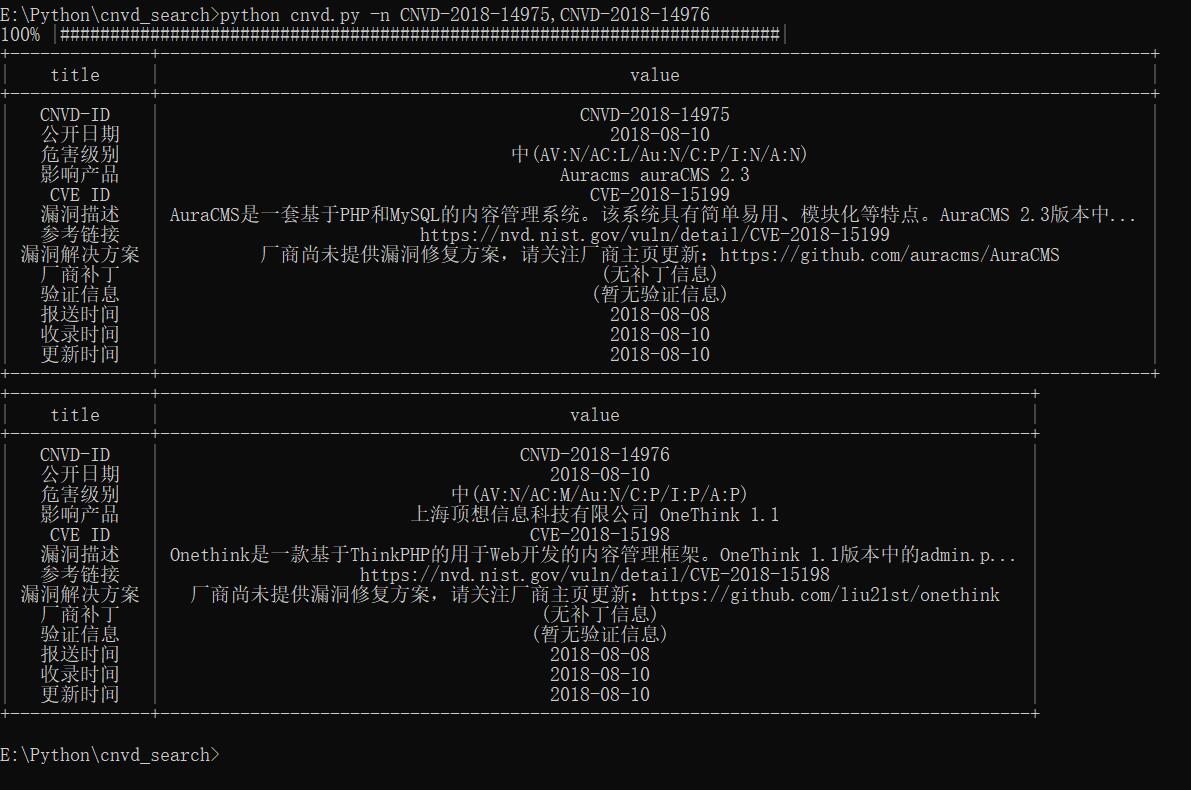
上脚本。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# author:Y4er
import requests
import argparse
import progressbar
import prettytable as pt
from bs4 import BeautifulSoup
headers = {
'Referer': 'http://www.cnvd.org.cn/flaw/list.htm',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
# 一个编号处理方法
def one(number):
url = 'http://www.cnvd.org.cn/flaw/show/' + number
tb = getinfo(url,number)
print(tb)
# 多个编号
def many(nums):
tbs = []
p = progressbar.ProgressBar()
for number in p(nums):
url = 'http://www.cnvd.org.cn/flaw/show/' + number
tb = getinfo(url,number)
tbs.append(tb)
for tb in tbs:
print(tb)
# 获取表格
def getinfo(url,number):
tb = pt.PrettyTable(["title","value"])
# 获取源码
r = requests.get(url,headers=headers).text
soup = BeautifulSoup(r,'html.parser')
# 获取数据
trs = soup.findAll(name="tr")[:13]
for idx,tr in enumerate(trs):
# print(idx,tr.get_text())
tds = tr.findAll(name="td")
title = tds[0].get_text().strip()
value = tds[1].get_text().strip().replace('\r','').replace('\t','').replace('\n','')
if len(value)>=60:
value = value[:60] + '...'
tb.add_row([title,value])
return tb
if __name__ == '__main__':
# 命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('-n',dest='number',help='input your cnvd number',required=True)
args = parser.parse_args()
if args.number==None:
print(args.print_help)
# 切片 判断是一个编号还是多个
nums = args.number.split(',')
if len(nums) == 1:
one(nums[0])
else:
many(nums)
原创文章,作者:Y4er,未经授权禁止转载!如若转载,请联系作者:Y4er
赞 (0)
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫
PHP-Audit-Labs:一个适合新手PHP代码审计的项目
« 上一篇
2018年8月10日 am11:20
一张验证码引发对DOS的思考
下一篇 »
2018年8月13日 pm10:38

